DB에 대해 공부하던 중 row정보를 어떻게 데이터베이스에 저장하는지 궁금해져서 공부해 보았다. PostgreSQL 버전은 17이다.
1. SELECT query plan
row가 어떻게 저장되는지 알기 전에 select가 어떻게 동작하는지 확인하는지 확인할 필요가 있다. 아래 임의의 DDL/DML을 작성한 예시를 통해 알아보자.
CREATE TABLE ternary
( a int NOT NULL,
b text NOT NULL,
c float
);
INSERT INTO ternary(a,b,c)
SELECT
i,
md5(i::text),
log(i)
FROM generate_series(1, 1000, 1) AS i;
ANALYZE ternary;
EXPLAIN VERBOSE SELECT t.* FROM tenrary AS t;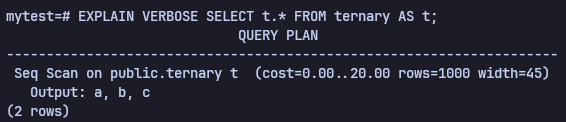
select를 호출하면 SeqScan Plan을 부르게 되고, SeqScan은 table에서 주어진 column에 해당하는 rows를 가져온다. 여기서 rows는 불러올 총 row 개수, width는 불러올 row의 평균 bytes이다.
Width는 4(int) + 33(text) + 8(float)로 가져온다. 여기서 column b는 variable length character type으로 1 byte + 32 string bytes로 이루어져 있다.
Chracter type에 대한 자세한 정보는 https://www.postgresql.org/docs/17/datatype-character.html를 참고
만약 모든 column이 아닌 a와 c에 대해서만 가져오면 어떻게 될까?
EXPLAIN VERBOSE SELECT t.a, t.c FROM ternary AS t;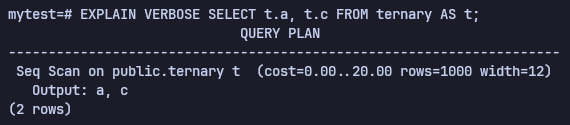
row개수는 똑같지만, width가 변경됬다. Width는 4(int) + 8(float)으로 a와 c의 타입 크기와 같다. 그리고 cost는 같은 것을 볼 수 있는데 t.* 와 t.a, t.c 둘다 cost가 20으로 같다.
다시 말하면 column에 따라 불러오는 page 개수가 변경되지 않고 같다는 소리이다.
이는 PostgreSQL이 Row-oriented DBMS로 구현했기 때문이다. 이에 대해 자세하게 알아보기 위해 Page와 Row가 어떻게 이루어져 있고 저장되는지 알아보자.
2. Page layout
PostgreSQL은 Row-oriented database로 한 row의 모든 column은 인접하게 저장된다. 그 말은 heap file 하나를 읽으면 저장된 모든 row의 column을 불러오게 되고, 이는 t.*이던 t.a를 사용하던 결국 다 가져오게 된다.
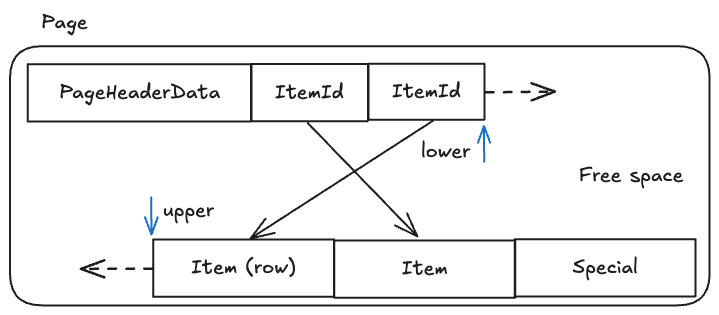
PageHeader에는 page와 관련한 정보가 저장되어있다. 대표적으로 최종 변경 기록이 끝난 지점을 가리키는 lsn, ItemId의 마지막 부분이면서 free space의 시작 부분인 lower, Item의 시작이면서 free space의 마지막 부분인 upper 정보를 담고 있다. 그리고 Item의 위치를 가리키는 ItemId (row pointer, lp라고도 불림), Item은 row 데이터(payload)를 통해 한 페이지를 이루게 된다. (postgresql에서는 item은 row,tuple을 의미합니다.)
PageHeader는 항상 24 bytes의 크기를 가지고 lower와 upper가 만나면 page는 꽉찬 상태가 된다. pageheader 정보는 postgresql에서 제공하는 pageinspect module을 통해 페이지를 볼 수 있다.
CREATE EXTENSION IF NOT EXISTS pageinspect;
-- page header 보기
SELECT *
FROM page_header(get_raw_page('ternary', 0));
-- row pointer와 payload 보기
SELECT *
FROM heap_page_items(get_raw_page('ternary', 0));Page header를 보면 다음과 같이 나온다.

Page에서 row pointer를 확인하면 다음과 같이 나온다.
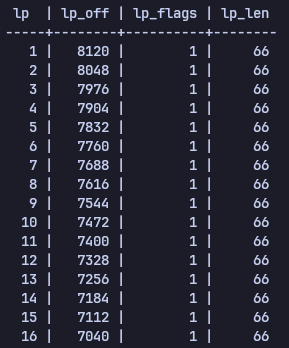
heap_page_items에서 나오는 나머지 정보는 row 관련 정보를 저장하고 있어 row를 어떻게 저장하는지 알아보자.
3. Row layout
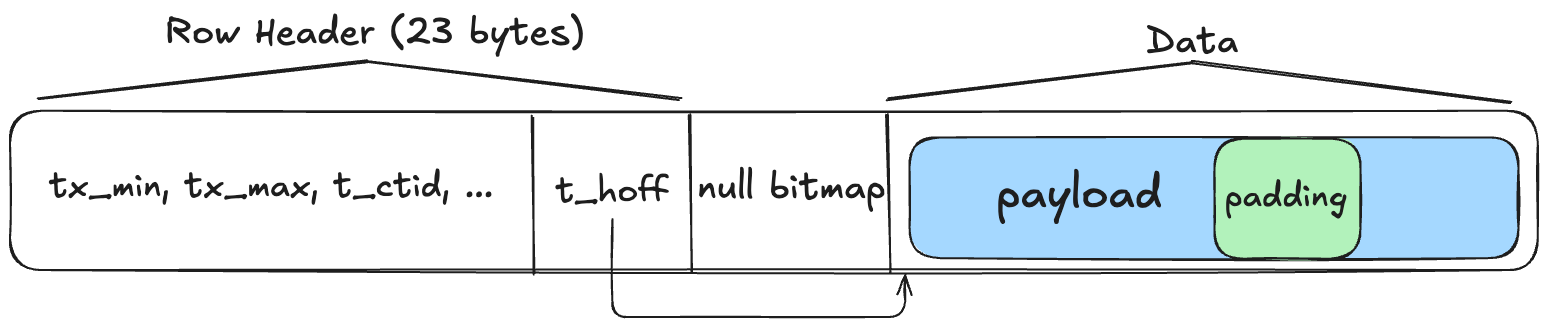
row는 다음과 같이 저장된다. Transaction에 필요한 정보와 payload를 가리키는 t_hoff로 이루어진 row header와 null 정보를 담는 null bitmap (column당 1 bit) 그리고 데이터를 담고있는 영역으로 이루어져 있다.
heap_page_items를 통해 살펴보면 다음과 같습니다. 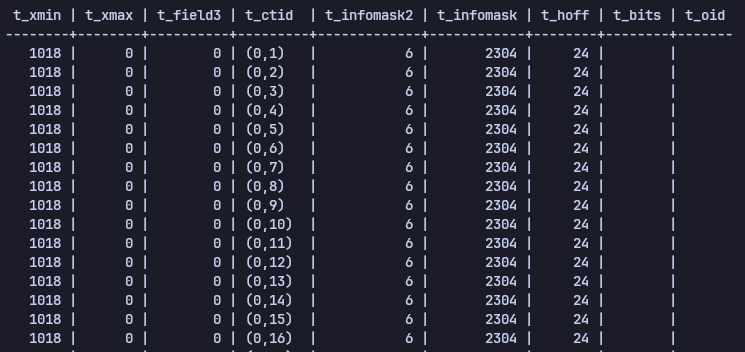
그리고 EXPLAIN에서 나오는 width는 payload에 해당되는 부분만 나온다. 해당되는 data 부분을 확인해보자.
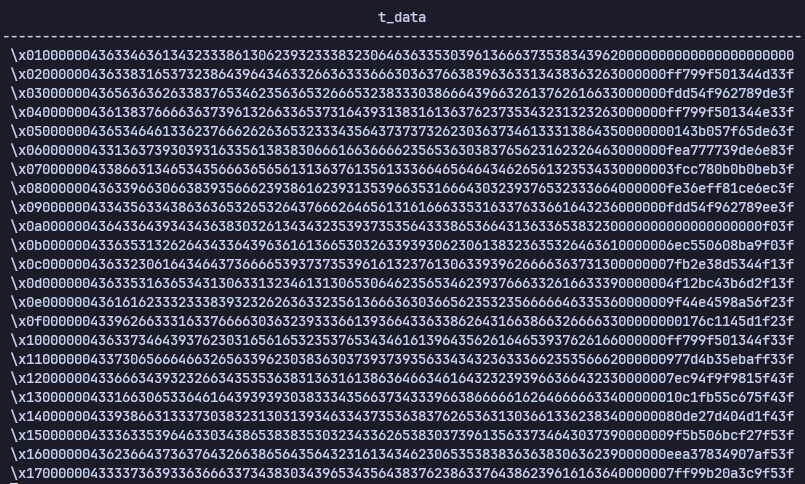
예시를 위해 2번째 데이터만 보자.
2번째 데이터의 값은 a는 2, b는 c81e728d9d4c2f636f067f89cc14862c, c는 0.3010299956639812이다.
먼저 데이터를 분리해보면 2는 int로 4 bytes 크기를 가지고 있고 02000000 값으로 나타나 있다. b에 값은 text로 여기서는 36 bytes아다. 여기서 앞에 43은 string을 저장할때 사용되는 1 byte이고, 마지막에 00 00 00 3 bytes가 padding으로 들어가 있는것을 확인 할 수 있다. c는 float으로 8 bytes이다.
모든 payload는 CPU와 memory가 빠르게 읽을 수 있도록 항상 align 되있어야 한다. 그리고 우리는 타입마다 align 값을 다음과 같이 확인 할 수 있다.
SELECT a.attnum, a.attname, a.attlen, a.attalign
FROM pg_attribute AS a
WHERE a.attrelid = 'ternary'::regclass
AND a.attnum > 0
ORDER BY a.attnum;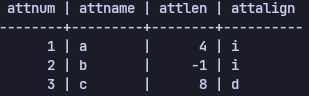
Column별로 데이터 정렬 방식이 지정된 것을 볼 수 있다. i는 4 bytes이고, d는 대부분 컴퓨터에서 8 bytes 이다.
4. Column 순서에 따른 space overhead
CREATE TABLE padded (
d int2,
a int8,
e int2,
b int8,
c int8,
f int2
);
CREATE TABLE aligned (
a int8,
b int8,
c int8,
d int2,
e int2,
f int2
);
INSERT INTO padded(d,a,e,b,f,c)
SELECT 0,i,0,i,0,i
FROM generate_series(1,100000) AS i;
INSERT INTO aligned(a,b,c,d,e,f)
SELECT i,i,i,0,0,0
FROM generate_series(1,100000) AS i;위 sql문은 2개의 같은 데이터 타입이지만 column 순서가 다른 테이블을 만들고 동일한 데이터를 추가하였을때 어떻게 공간이 차이가 나는지 확인하기 위한 코드이다.
먼저 64-bit 컴퓨터에서는 8 bytes 단위로 읽기 때문에 int2는 2 bytes, int8은 8 bytes로 padded 테이블에서는 2(int2) + 6 (padding) + 8 (int8)이 3번 반복되서 48,
aligned 테이블에서는 8 (int8) + 2(int2)가 3번 반복되서 30 bytes에 2 bytes padding이 추가된 32 bytes가 된다.
공간적으로 얼마나 효율적인지 확인하려면 pg_freespacemap module을 사용하여 freespace(upper-lower)가 남아있는지 확인할 수 있다.
CREATE EXTENSION IF NOT EXISTS pg_freespacemap;
SELECT COUNT(*) FROM pg_freespace('padded');
SELECT COUNT(*) FROM pg_freespace('aligned');확인해보니 padded는 1870, aligned는 736으로 2배정도 차이나는 것을 볼 수 있다.
EXPLAIN VERBOSE SELECT * FROM padded;
EXPLAIN VERBOSE SELECT * FROM aligned;또한 위 sql문을 사용해서 얼마나 비용이 차이가 나는지 확인하면,
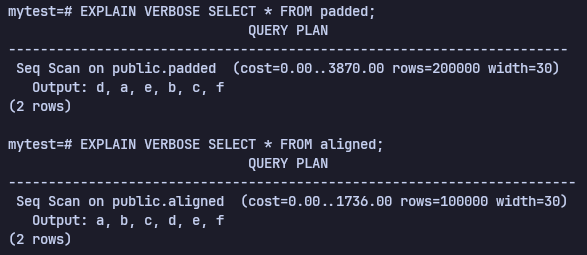
3870에서 1736으로 2배 이상 감소한 것을 볼 수 있다. 만약에 최적화 마지막 단계에 있다면 column의 위치를 바꾸는 것 만으로도 비용을 줄일 수 있다.